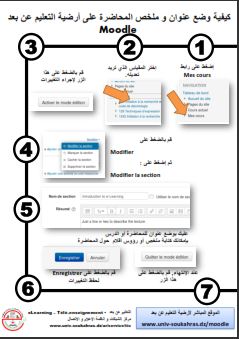
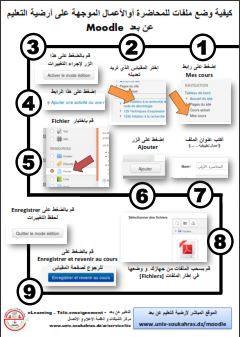
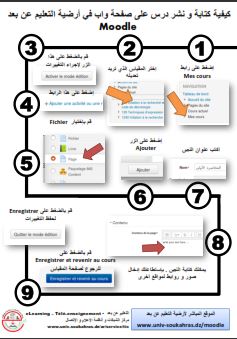
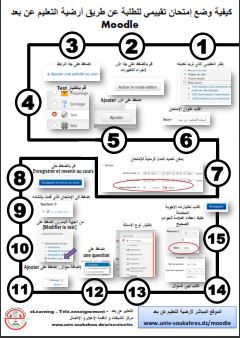
Login Email: Password: Login Reset Password Information for students The university students can get a site account via this link. New staff accounts New academic and administrative staff can get a site account via this link. Information for professors