معلومات للطلاب
يمكن لطلاب جامعة سوق أهراس الحصول على حساب في الموقع من خلال هذا الرابط.
حسابات الأساتذة والموظفين الجدد
يمكن للأساتذة والموظفين الجدد الحصول على حساب في الموقع من خلال هذا الرابط.
معلومات للأساتذة
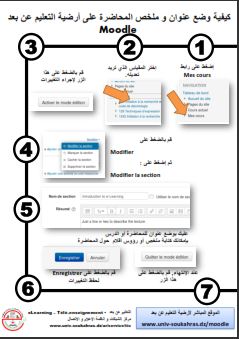
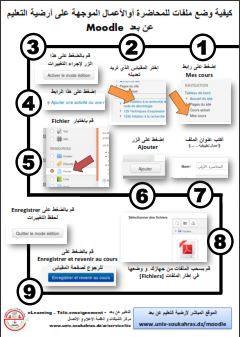

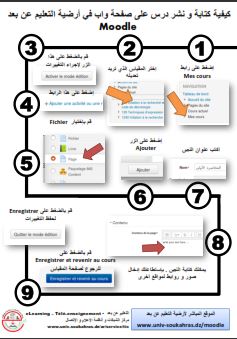
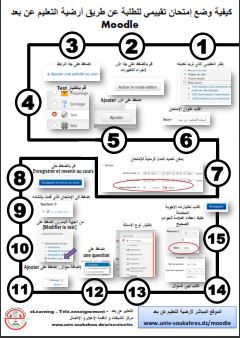
يمكن لطلاب جامعة سوق أهراس الحصول على حساب في الموقع من خلال هذا الرابط.
يمكن للأساتذة والموظفين الجدد الحصول على حساب في الموقع من خلال هذا الرابط.